Integration and Collaboration in AI Research Work
Video 8 in a series on Claude Code
Part 8 of a series on AI coding tools for empirical research, accompanying my Markus Academy video series.
This post is the capstone of the series. The earlier posts were about getting the agent to do things: setting up, analyzing data, scraping, handling large datasets, writing, sandboxing and specifying how agents think (skills). In most of those demos, I skipped over a step—Markus and I would look at the output, nod, and move on. This post is about what you do after the agent hands you a finished-looking result — e.g. real research.
A framing I find useful is about costs. AI has collapsed the cost of doing certain kinds of work: coding, data construction, empirical analysis, etc.1 The cost of verifying that the work is correct has moved much less. We’re economists; costly verification is an idea we’ve struggled with for decades. Now as the cost of actions has fallen, with a consequent increase in the relative cost of verification, many of us find ourselves doing a lot of the cheap activity, with potentially less verification. As a result, you can accumulate what people have started calling verification debt: a growing pile of AI-produced results yo haven’t actually checked.

A two-by-two makes the problem concrete (the picture above comes from a nice post by Clifford Russell on these challenges in the context of software engineering) . Put the cost of making something on the x-axis and the cost of verifying it y-axis. The danger zone is the cell where things are now cheap to make but still expensive to verify.
Expensive-to-make work forced you to go slowly, and verification happened as a byproduct of doing. Now the code arrives finished, and the understanding is the thing you still have to build.
In the video, Markus asked a good question: how is this different from just not using YOLO mode and approving each step as it happens? The answer is a function of how much you verify and internalize the work that the agent is doing. The more autonomy you provide, the worse the problem gets (e.g. the ladder from the the post on sandboxes). If the agent works alone for 25 minutes and comes back with a repository, a figure, and a headline estimate, the verification simultaneously arrives at the end.
So the question for today: how do you build a work environment where verification is tractable in research?
The three things we’ll discuss today are not AI tooling, at least in essence. It’s the tooling software engineers built for exactly this style of problem: reviewing others’ code and work. But AI happens to supercharge these workflows.
1. Review the code as reported — git and a GitHub repository you (and your LLM) can read
2. Give feedback that routes back — to the agent, to coauthors, and to the permanent record.
3. Publish the results into the draft — each number in the paper traces to code by integrating Github into Overleaf
The demo: an IPO event study
I wanted something practical rather than a lecture, and the timing helped: SpaceX just went public, Hanno Lustig has been posting about it, and so a natural empirical question for us to study is how stock prices adjust after firms IPO (since SpaceX has been angling to get themselves included in indices where passive investment money can provide a significant pop in demand).
There’s a well-documented post-IPO underperformance pattern, so I asked Claude to replicate it. To Claude Code, I gave the task to estimate abnormal returns after IPOs.2 Use Jay Ritter’s IPO data as the event sample, and CRSP (via WRDS, which I have credentialed access to) for aftermarket returns and a benchmark. Report the average effect with a figure and a table.
I was deliberately vague about how exactly Claude should implement this.There are a few obvious decision branches: cumulative abnormal returns versus buy-and-hold returns; which benchmark to use; which event windows, how to handle delisting; how to match Ritter’s firms to CRSP identifiers; etc. I left this to the agent and I would eventually need to decide if the decisions were appropriate, similar to if an RA made it for me.
What I did specify, in detail, was the paper trail:
Commit the code into a git repository locally at every meaningful checkpoint, with messages that say _why_, not just what.
Keep a
DECISIONS.md: each methodological choice, the alternatives rejected, and a confidence level.Keep a
LOG.md: a plain-language narrative a coauthor could follow.Print a sample-attrition table at every stage—the N, what dropped, and why.
I let it run in auto mode for about 25 minutes. The resulting repository is public at github.com/paulgp/ipo-bump. I asked for the trail precisely so the work could be reviewed. That’s the discipline I want to convince you of: the request for verifiability goes in the prompt, before the work happens.
Part A: Review the code as reported
Two minutes on version control
What’s git? Here’s the cursory version. The joke about git is that if you ask someone who really knows it, by the time they’re done you never want to hear about it again. It’s built for enterprise software teams and has a hundred features researchers will never touch. You need about five of them.3
Version control is a committed set of historical versions of your work. We’ve all lived the alternative: working_code_v1.do, then _v2, then _final_final. What you actually want is one file plus a complete record of how it changed over time—track changes, but for code. That’s what git does: it looks at a folder, computes differences between versions of files, and keeps a permanent record of every saved state.
A commit is the act of saving a state into that record. Markus asked whether committing locks you in—no, it’s a snapshot, and you keep working afterward. If you’re a Stata person, it’s like a preserve statement: “record things exactly as they are right now.” GitHub is a remote website where the record can live in addition to on your computer, so coauthors can see it, you can use it across computers, and so you can read it with good tooling. A diff is the comparison between two states—new lines shown in green, deleted lines in red—which is exactly the “marked-up changes” view you’d want when reviewing anyone’s work.
One more piece, because Markus asked: the .gitignore file lists things git should never record. In our repo, Claude put the raw WRDS extracts in there (you don’t want big data files in the history—collaborators pull those themselves) and my database password. It actually listed the password file twice in my gitignore file, in two syntaxes. I don’t know why, but I had told it in no uncertain terms not to commit my password, and I appreciate the paranoia—I really did not want to make this video and simultaneously publish my WRDS credentials to the world.
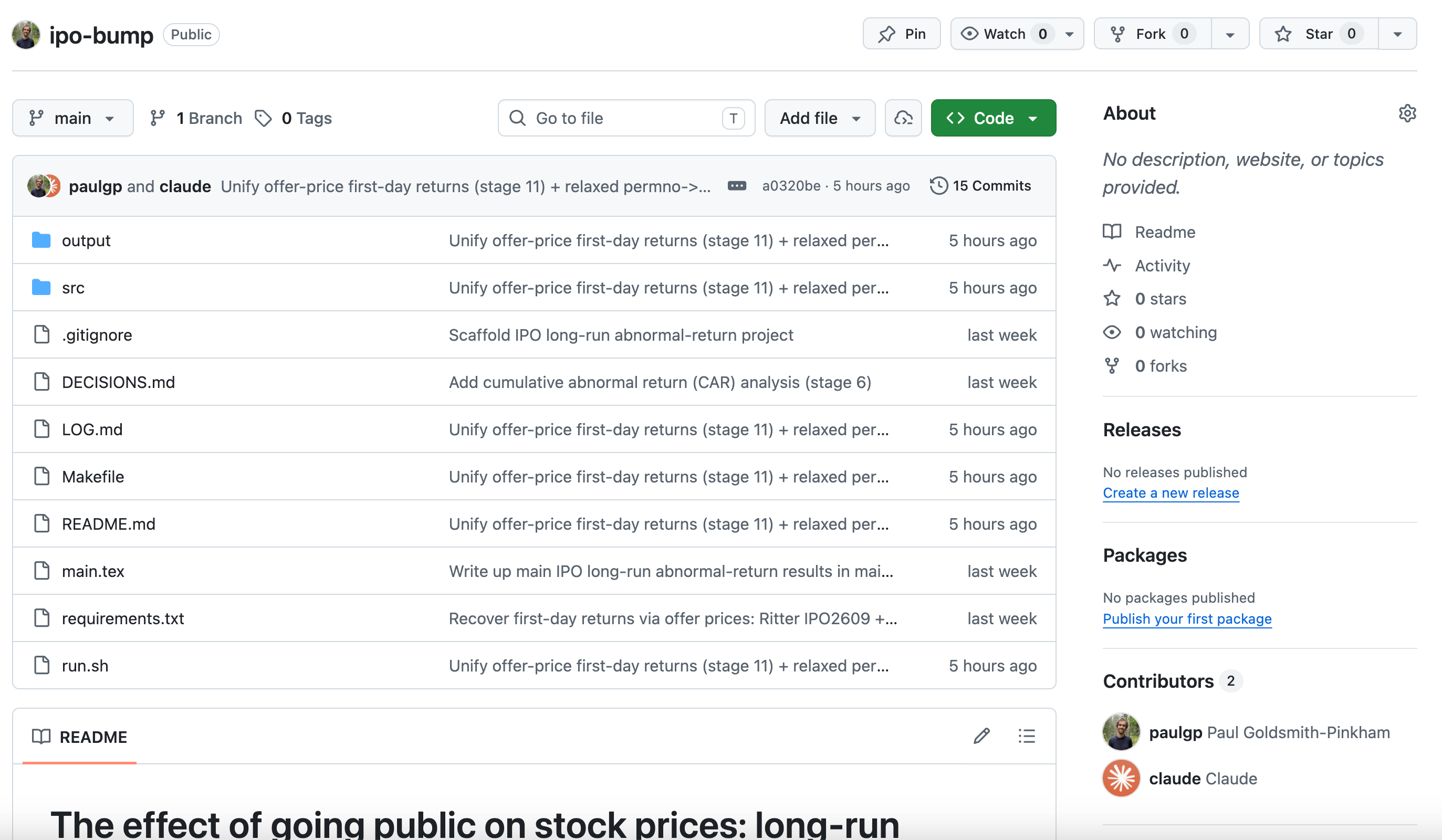
Reading the repo like a referee
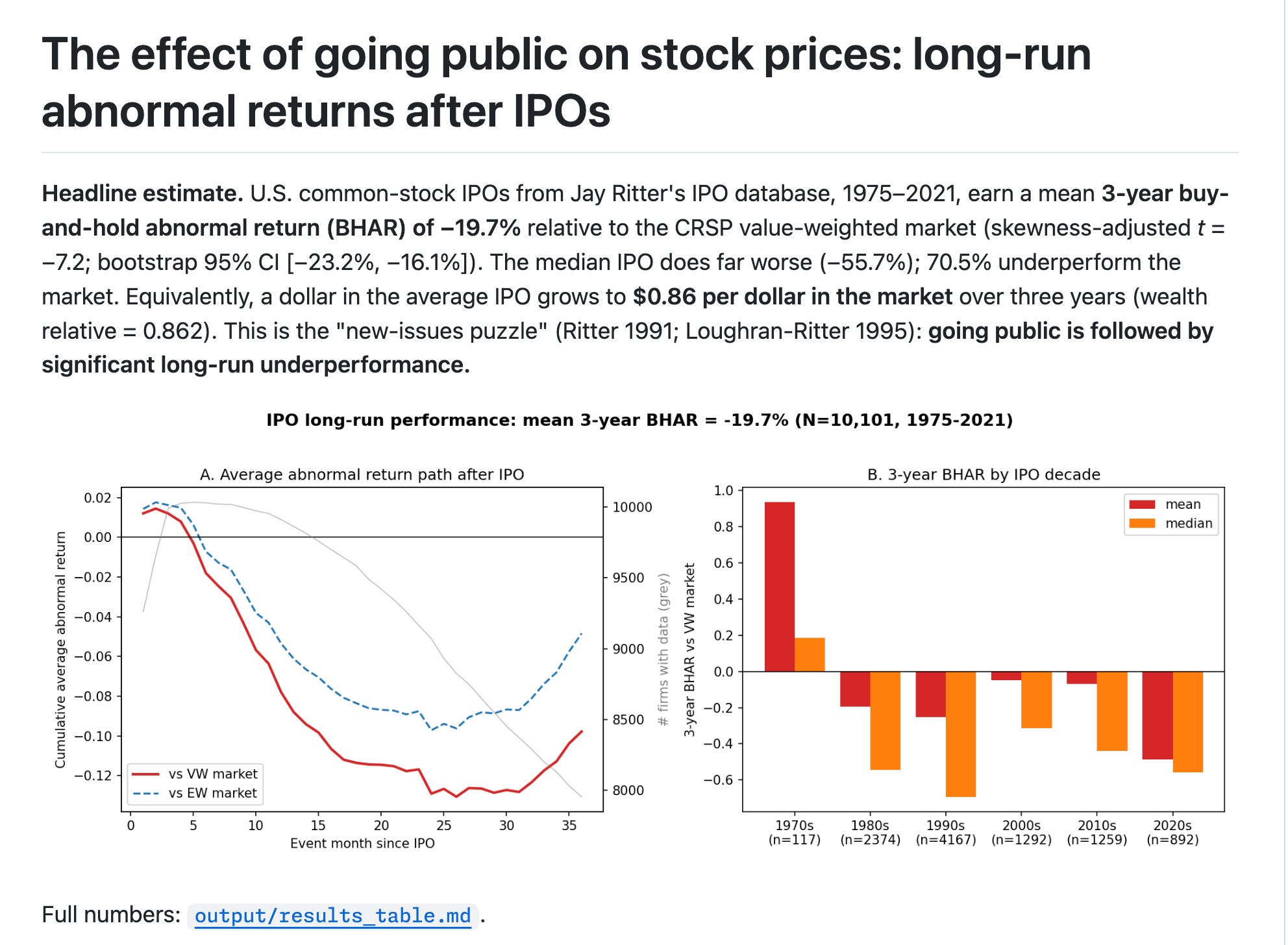
The agent hands back a repository with full history, a figure, a table, and a headline estimate: U.S. common-stock IPOs from Ritter’s database, 1975–2021, earn a mean three-year buy-and-hold abnormal return of −19.7% relative to the CRSP value-weighted index. In plainer terms: a dollar invested in these IPOs at the close of their first trading day grows to about $0.86 for every dollar the market would have delivered over the same three years, and 70.5% of individual IPOs land below the market. That passes the initial sniff test—it’s the post-IPO underperformance pattern the literature documents.
The mental model for this workflow is that work from an AI is work from your RA. This is code that you did not write, but you have a rough sense of what it should do. Unfortunately for you, it will often pass the sniff test — it looks finished and polished. But now the question is whether the task was done correctly.
Fortunately, you know how to do this! Every senior coauthor has reviewed a junior person’s work; every software engineer has done code review. Nothing about this task is new. What’s new is that most researchers never adopted the structure that makes it efficient.
The structure is the commit history. Because I asked for commits at every checkpoint, the work arrives in chunks: scaffolding, data loading, matching, return calculation, estimation and output. Commits change the unit of verification. You review one bounded diff at a time instead of confronting 800 lines of code at once.
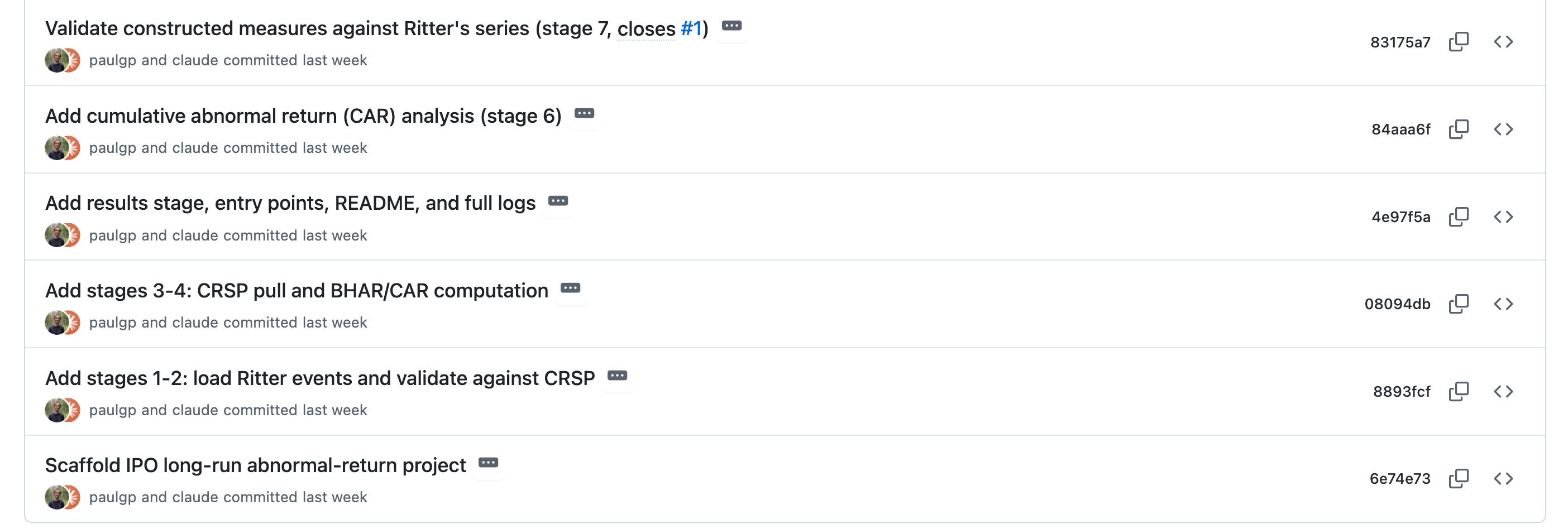
You can walk the sequence as a story (pull → clean → match → compute returns → estimate) and ask whether the order makes sense. And when you later request a change, GitHub shows you only what changed: a 12-line diff against a baseline you’ve already reviewed. A repo with one giant commit doesn’t give you any of this; it’s just a blob with a `.git` folder attached.
The trail, and its limits
In Decisions.md, I asked Claude to record choices along the way. However, the decisions file claimed it had computed cumulative abnormal returns as a robustness check. But it hadn’t! There was no CAR figure, no CAR code. It also mentioned calendar-time portfolios—a useful alternative—and didn’t do those either. It claimed work it never did. Markus asked whether you can prompt this away—”please be careful and do every step”—and you can push in that direction, but the more reliable fix is smaller task chunks, which are easier to complete and easier to check. These systems can be as lazy as we are.
Concretely, here’s the checklist I’d work through for this particular task, each item a place where the code can be perfectly clean and the answer still wrong:
Did it actually use Ritter’s event dates, or silently construct its own? (I traced this one through the data-loading commit: it builds the event date from Ritter’s
offer_datefield, correctly. We are trusting Jay here, but as Markus said—in this life, we trust Jay.)Do the computed first-day returns reconcile with Ritter’s published first-day returns, or does the repo just claim they do?
How are delisted firms handled—are they in the sample, and which way does dropping them bias the mean?
Is the benchmark defensible, and does the sign survive the obvious alternative (CAR versus buy-and-hold)?
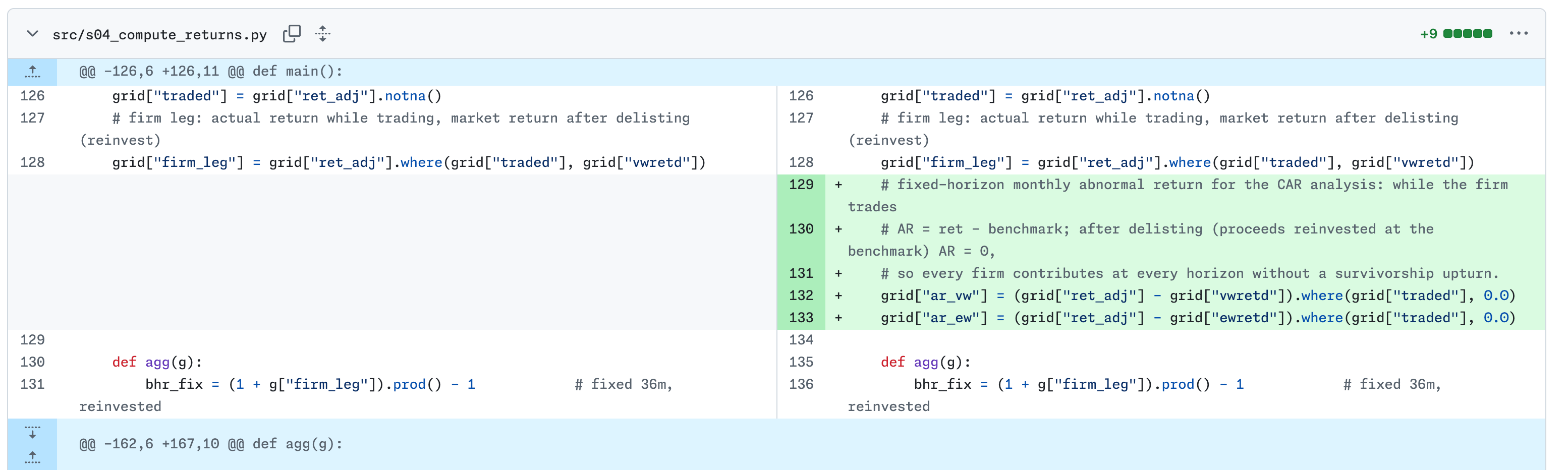
That last one I handled by iterating live. I went back to the command line and asked Claude to add a cumulative abnormal return analysis alongside the buy-and-hold version, then commit and push. A few minutes later there’s a fifth commit, and the review burden is only the new diff. The CAR estimate comes in at −17.8% at 36 months against −19.7% for buy-and-hold, with the mean-median gap looking different across the two measures.
Part B: Feedback that routes back
Finding a problem is half the job. Getting the fix made—and recorded—is the other half. There are three audiences for your feedback: the agent, your coauthors, and future-you. The useful discovery is that one piece of machinery serves all three: GitHub issues.
An issue is a titled note attached to the repository—a to-do item with a discussion thread. Here’s the loop I demonstrated in the video. Remember the reconciliation question from the checklist? I opened an issue: “Validate return measures against Ritter’s initial returns—Ritter publishes first-day returns for these IPOs; compare our constructed measures against his and report how well we match.” Writing it felt like writing a Slack message to an RA, except it lives permanently next to the code.
Then, in a fresh Claude session with no memory of anything, I typed:
“Please review issue #1 on GitHub, code up an answer, then commit and push. Use the `gh` command-line tool
”
The agent pulled the issue text, explored the repo to orient itself, did the analysis, pushed the result, and closed the issue. You don’t need to sit and watch; you could kick this off and check the answer from your phone. (You can see where this is heading—an agent that watches the issue tracker and handles items as they’re filed. We won’t build that in this series, but the shape of it should be visible.) You can see the issue here
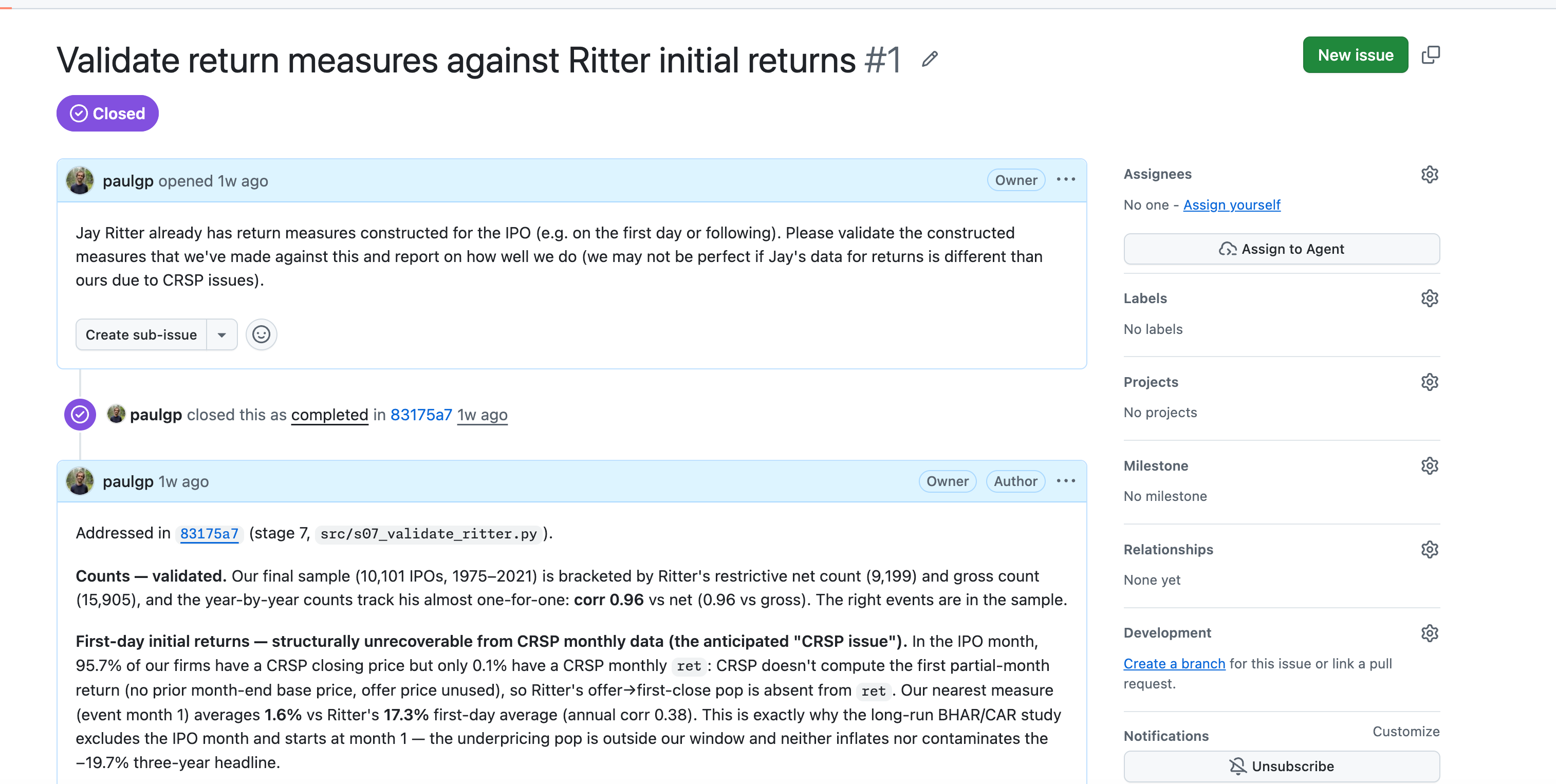
The answer taught me something real: the exact first-day return is unrecoverable from the data as pulled, because Claude had built everything on CRSP’s monthly files. Monthly data has a closing price for the IPO month but can’t isolate the first trading day.
So the loop continues: I opened issue #3, “Reconstruct the analysis using daily data—we discovered in #1 that the pipeline uses monthly CRSP returns; switch to daily and aggregate up so we can match Ritter and support higher-frequency analysis.” Typing `#1` in the text auto-links the earlier issue, so the reasoning chain is preserved. Then, back at the command line: “Please tackle issue #3.” That issue is closed now too: the daily reconstruction confirms the monthly results, and along the way the repo grew a first-day-return analysis that recovers offer prices from Ritter’s files, Capital IQ, and SEC 424B prospectuses. Each round of review generated the next round of work, and the record shows the whole chain.
Two practices make this loop work well. First, be specific. “This seems off” gets you a vague fix. Name the join, the variable, the count you expected—”please diagnose why we lose four IPOs at the CRSP match stage” is a prompt the agent can act on and you can verify. Second, anchor feedback to code where possible: GitHub lets you comment on a specific line of a specific commit, so “check the merge keys on this line” carries its own context.
For coauthors, the same record does double duty. An email thread about the benchmark choice can get lost in an inbox, while an issue is remains indexed and referenced to the code and project. You can see what’s been checked, by whom, and what’s still open—verification distributed across the team and made visible. A trick I’ve come to like: after a seminar, file each question you got as its own issue, then ask the agent to go through them and draft the best available answer for each, flagging which ones require actual new analysis.
Markus asked about pull requests (PR), which you’ll see mentioned everywhere. A PR is a request to fold one branch of work back into the main line—”I’m done with this piece, please pull it in”—and it’s where professional code review formally happens. For a research team it’s worth adopting eventually, but issues alone get you most of the value, so I kept the demo there.
Markus also asked whether the verification itself can be done by another AI, such as Gemini or ChatGPT reviewing Claude’s code. It can, and people do run exactly that workflow; a second model reviewing the first catches real things. But I keep coming back to the line from the 1970s IBM training manual that I used in a previous post: a computer can never be held accountable. You still need a human being signing off on the task. The main goal of this workflow is to make this as painless and structured as possible.

Part C: Publish the results into the draft
The last leg is getting results into the paper. This part is probably the least necessary, but if you have AI work on compile and write parts of your paper, having a documented pipeline becomes more important.
A cardinal rule—which predates AI but matters more now—is that no number in the draft gets typed by hand.4 The pipeline emits results.tex and figure.pdf; the paper pulls them in using input and \includegraphics{}. Then, whenever you update the analysis, it is straightforward to update the paper. With AI in the loop, you avoid having the results be written into the paper based on the model’s context window, but are instead directly mapped by code.
The integration that makes this smooth: Overleaf can sync directly with a GitHub repository. (Note: this sits behind Overleaf’s paid tier, though only the project owner needs the subscription—once the project is linked, any collaborator on it can hit the sync button. Markus’s alternative also works: Overleaf syncs with Dropbox, so you can point the pipeline’s output folder there instead—but Dropbox sync is a premium feature too, so there’s no free route to automatic syncing.) In the video I linked the ipo-bump repo to an Overleaf project, pulled, and every file appeared—figures, tables, the logs. I wrote a skeleton document referencing the results figure, pushed from Overleaf back to GitHub, had Claude write up the results section from the command-line side, and pulled again in Overleaf. The draft updated with the new text and the current figures. Nobody copied and pasted anything, and the draft’s own edit history now lives in the same git record as the code.5

The payoff is provenance. When a coauthor questions a coefficient, you walk backward: which table, which script, which commit, which logged decision. “Let me dig through my files” becomes a five-minute trace by Claude Code. In most cases I would simply ask AI to figure out where a decision got made, and since the commit history keeps track of all changes, it is a quick task.
Note that a correctly wired pipeline guarantees the number in the paper matches the number the code produced but doesn’t promise correct code. Clean provenance can faithfully publish a wrong estimate—which is why Part A comes before Part C. Review the method, then wire it into the draft.
Wrapping up the series
The loop this post assembles—act, review, publish, critique, re-run—works well for me. I still have far too much to review, but it keeps it organize and me sane.
1. Ask for the trail before the work happens
2. Review commits, not full codebases. The unit of verification should be a bounded diff.
3. Documentation is a map, not a verdict. LLMs are happy to claim results have been done that are not in fact there. Make a point of verifying (and even consider having another AI review)
4. Route feedback through issues. Use issues to keep track of tasks! The paper trail is invaluable to humans and agents.
5. No hand-typed numbers. Code emits, the draft ingests, git connects them. And review the method before you wire it in.
AI is good at this. Researchers mostly never adopted git—the perceived setup cost was too high for the benefit. That cost is now roughly zero. Tell Claude at the start of a project that you want everything tracked in git and GitHub, and it just does it, happily—it has the spirit of a good software engineer living somewhere deep inside. You get the best practices without the years of accumulated scar tissue that software engineers paid for them.
Markus closed by asking where this all goes in one year, in five. Honest answer: five years is unknowable, and even one year ago looked completely different from today. My guess is that the rough edges—the feeling of being in the Matrix at a command line—smooth out, and it becomes much clearer which parts of the workflow are human problems and which are computer problems. I don’t think this automates research away; it’s comparative advantage all the way down, and taste, judgment, and accountability stay on our side of the ledger. Thirty years ago, running a regression with many fixed effects was a real computational constraint that shaped what questions people asked. Now we run a thousand of them without thinking. Verification of AI-produced work will feel like that eventually, once the tooling makes it routine—it will still matter just as much, and it will have stopped being the constraint.
Thanks for following along with the series. I’d like to hear what your biggest pain points are with these tools—that’s what future posts will get built from.
I am not a theorist, but I’m sure the many "tedious” parts of theory have also been reduced as well, in an analogous fashion.
If. you’re interested in abnormal returns, I have a whole paper with Tianshu Lyu on estimating causal effects in financial return data
My colleague Corey had a better line about git.
Things that are wrong in the age of AI:
1. you need to know how git works.
2. you don’t need to use git.
Like all rules, the point is that we constantly flagrantly break them.
If you’re familiar with git, Overleaf basically keeps it’s own repo folder and can push and pull commits like on your own folder. It will do its best to rebase and harmonize code without throwing issues to you, but stuff can get screwed up. AI will usually be able to fix it if so.